
Лаборатория данных Теплицы исследует, как российское гражданское общество ведет коммуникацию в Интернете, в том числе, на сайтах и в социальных сетях. Все данные мы собираем в датасет, который назвали «Грядка». Одной из частей «Грядки» является датасет по ВКонтакте с 875 группами и пабликами представителей гражданского общества. Всего мы скачали и проанализировали 267 010 постов ВКонтакте из нашей выборки за период с января 2022 года по ноябрь 2023 года.
В предыдущем исследовании мы рассказали, какие данные собрали и описали их характеристики, а в этой работе исследовали, что влияет на повышение коэффициентов охвата и вовлеченности ВКонтакте.
Как оценить популярность поста?
В прошлом исследовании мы ввели такие понятия, как коэффициенты охвата и вовлечённости. Первый мы считали как количество просмотров, деленное на количество подписчиков, то есть это не то же самое, что обычный охват, который исчисляется в просмотрах. А коэффициент вовлеченности пользователей мы оценивали следующим образом:
(количество просмотров + репостов + комментариев + лайков) / количество подписчиков
Мы использовали такую же метрику коэффициента охвата при анализе других соцсетей, например, в нашем исследовании гражданского общества в Telegram и в материале по Instagram. Коэффициент вовлеченности немного отличался по соцсетям, поскольку в Telegram, например, еще есть реакции, которые отличаются от лайков. Но суть та же самая – количество взаимодействий, деленное на количество подписчиков. Мы хотим сравнить эти метрики и результаты между собой.
Важность параметров
Мы попробовали применить несколько предсказательных моделей машинного обучения, чтобы описать, какие параметры предсказывают охват и вовлеченность. Такие модели иначе называются регрессионными. Они позволяют выявить взаимосвязь между разными параметрами и предсказать поведение одних при изменении других. Это способ анализа данных для прогнозирования значений одной количественной переменной на основе других, он помогает понять, какие переменные больше влияют на изучаемую, то есть, в нашем случае, на коэффициенты охвата и вовлеченности.
Для начала мы выяснили, какие параметры связаны между собой и много ли их. Во ВКонтакте параметры будут зависеть друг от друга, потому что, например, в более длинных текстах может быть больше эмодзи, значит, количество эмодзи и длина текста будут как-то связаны.
Мы изучили длину текста поста (в символах), тип приложения к посту (фото, видео, документ, опрос или ничего), эмоциональную окраску (иначе говоря сентимент), день недели публикации, количество эмодзи в посте.
Картинка 1. Скоррелированность параметров между собой
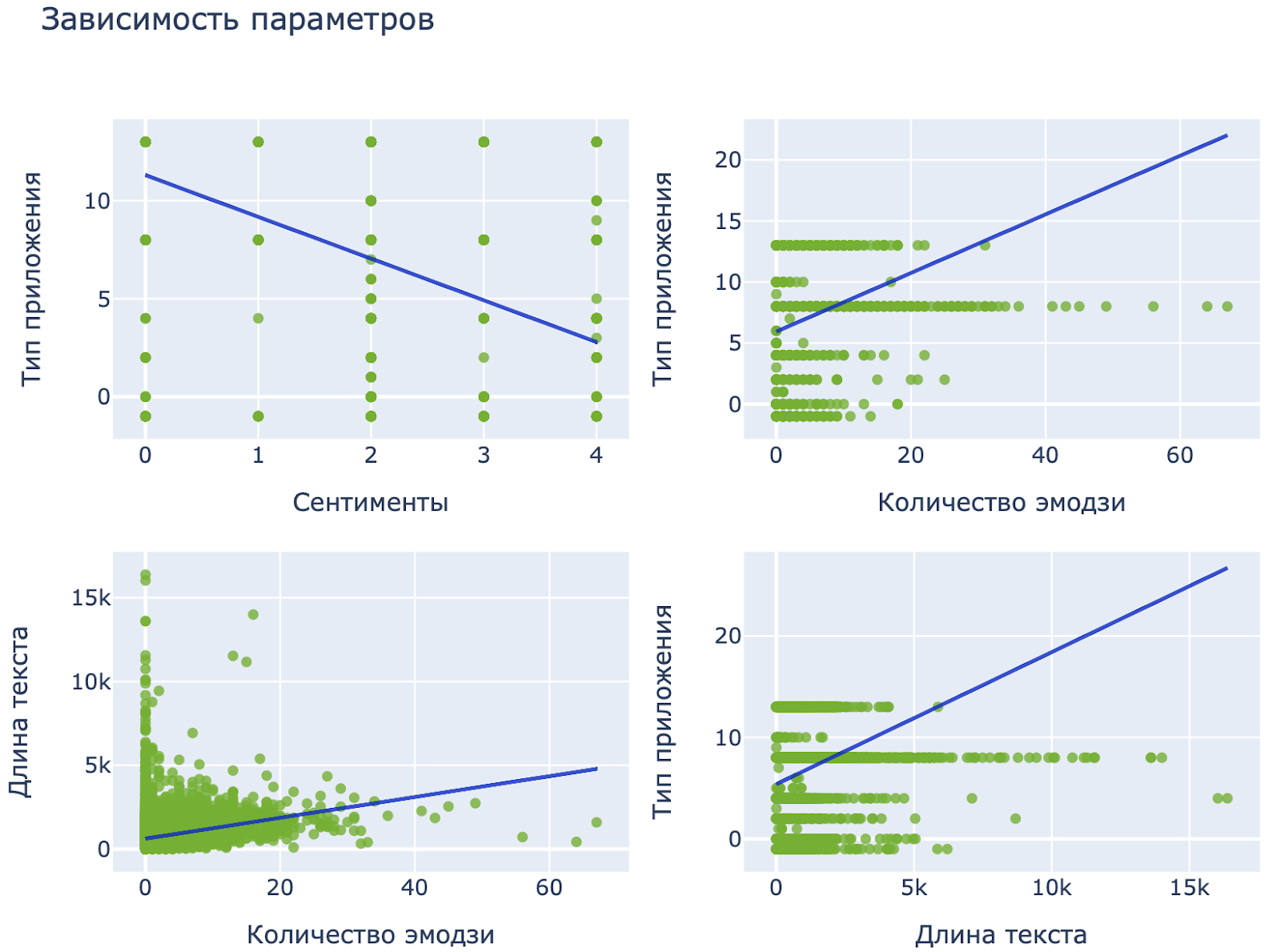
Как мы уже сказали, длина текста, ожидаемо, скоррелирована с количеством эмодзи, поскольку чем больше текста, тем больше эмодзи могут быть в нем применены. Тип приложения (приложены ли к посту видео/фото/документы или ничего) тоже связан с длиной текста, потому что есть посты без текста, но с приложением. И тип приложения по этой же причине связан с типом эмоциональной окраски, ведь в постах с малым количеством текста нет никакой окраски, и количеством эмодзи. Единственный независимый параметр – это день недели, он связан только с коэффициентом охвата, что хорошо, потому что коэффициент охвата это как раз та переменная, которую мы хотим предсказывать. Мы проанализировали, как и в какой степени коэффициент охвата связан со всеми этими параметрами.
Модель «KNN регрессора» и метрика, показывающая важность перестановок – не сошлась на наших данных
В первом эксперименте мы использовали модель «KNN регрессор» и применили к ней метрику важности перестановок. KNN регрессор – это метод, который для каждого нового анализируемого поста находит другие похожие посты и на основании их показателей предсказывает показатели введенного поста. А метрика важности перестановок показывает для каждого из параметров, насколько он важен для изучаемой переменной (в данном случае —коэффициента охвата). Мы по-очереди перемешиваем данные по каждому отдельному параметру (длина текста, количество эмодзи и т.д.) и смотрим, снизилась ли после этого точность прогноза коэффициента охвата.
При проверке этой модели на собранных данных мы выяснили, что она плохо предсказывает коэффициент охвата. Модель не просто не учитывает параметры, она использует их неправильно. Тем не менее, мы приведем здесь результаты для сравнения с другими подходами.
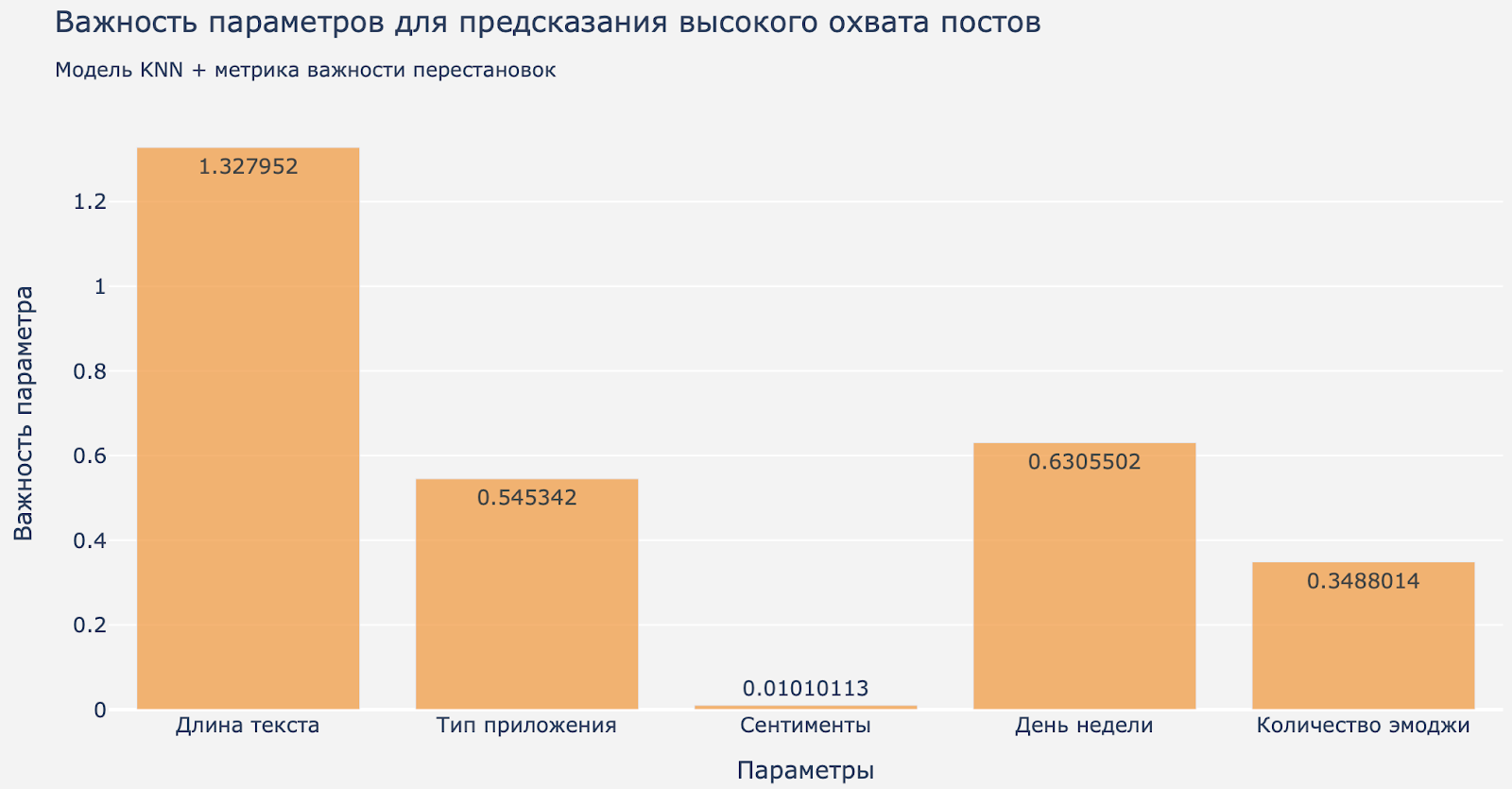
Картинка 2. Важность параметров для предсказания высокого коэффициента охвата постов на основе модели KNN регрессора и метрики важности перестановок.
После этого мы попробовали использовать модель ElasticNet, так как она более эффективно справляется с переменными с сильными взаимными связями, что актуально в нашем случае, потому что у нас переменная «длина текста» связана сразу с несколькими другими. Она сработала лучше, но и у нее вышла низкая точность. Единственная переменная, которая учитывается этой моделью при предсказании охвата — длина текста, и то, она учитывается незначительно.
По регрессионной модели XGBoost самый важный параметр — длина текста.
Далее мы построили модель XGBoost. Подробнее про нее можно прочитать в наших предыдущих исследованиях (например, в исследовании по Instagram). Точность этой модели тоже близка к нулю в среднем на нескольких экспериментах, как и у модели ElasticNet.
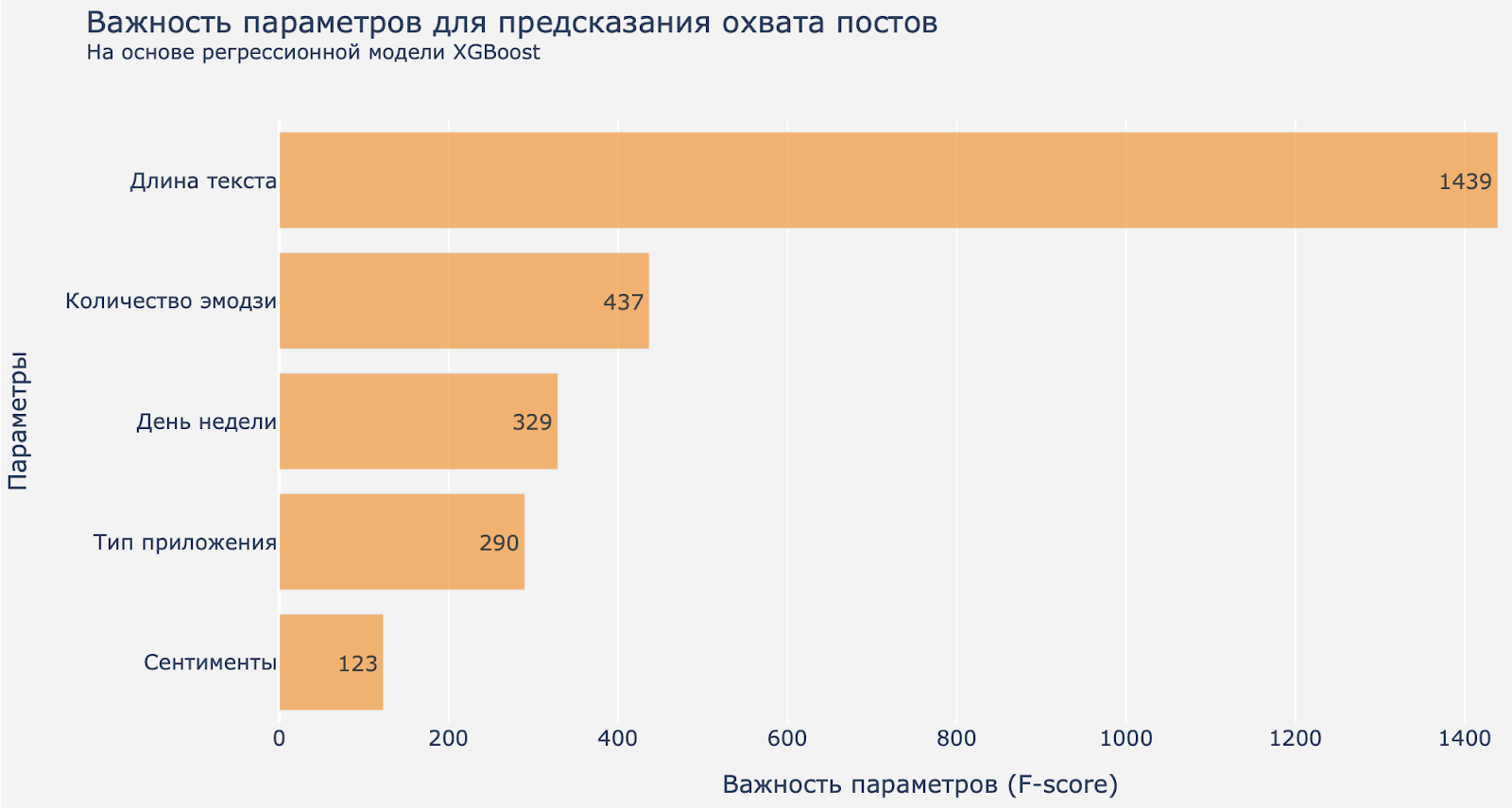
Картинка 3. Важность параметров для коэффициента охвата поста по модели XGBoost.
Эта модель тоже выбирает длину текста как важный параметр для коэффициента охвата. А количество эмодзи, как мы знаем, связано с длиной текста, поэтому этот параметр на втором месте и по сути не добавляет в модель никакой новой информации.
Но как сделать модель, которая хорошо бы описывала наши данные? Мы решили сделать коэффициенты охвата и вовлеченности не количественными, а категориальными, то есть спрогнозировать не точную цифру, а примерный уровень, а потом предсказывать, насколько параметр влияет на точность предсказания.
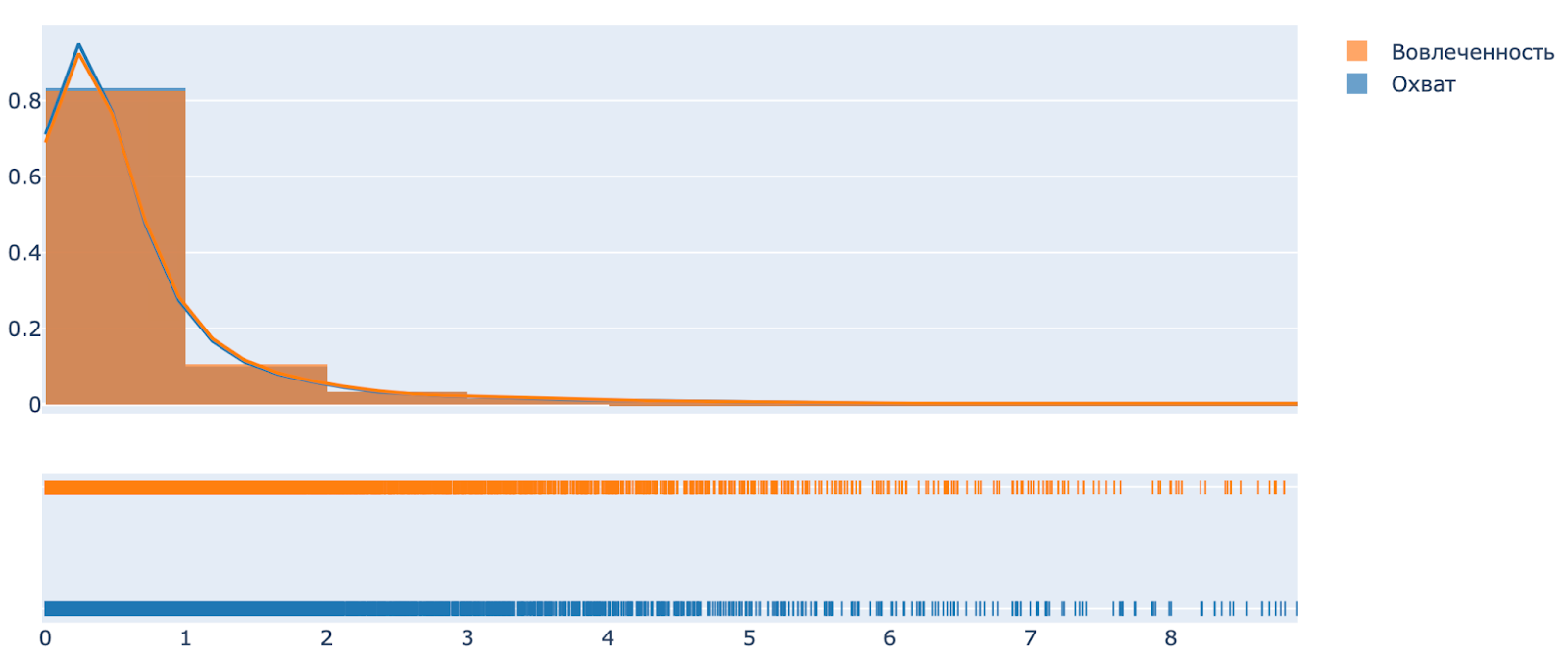
Картинка 4. Распределение постов по охвату и вовлеченности.
Мы посмотрели на распределение постов отдельно по коэффициенту охвата и вовлеченности и решили распределили их на 4 категории. Поскольку наибольшая часть постов находится в группе от 0 до 1 и по охвату, и по вовлеченности, мы разделили эту группу на две части, до 0.5 и от 0.5 до 1. Следующая группа постов от 1 до 4, и потом всё, что больше 4. Всего 4 группы отдельно по коэффициенту охвата и по коэффициенту вовлеченности.

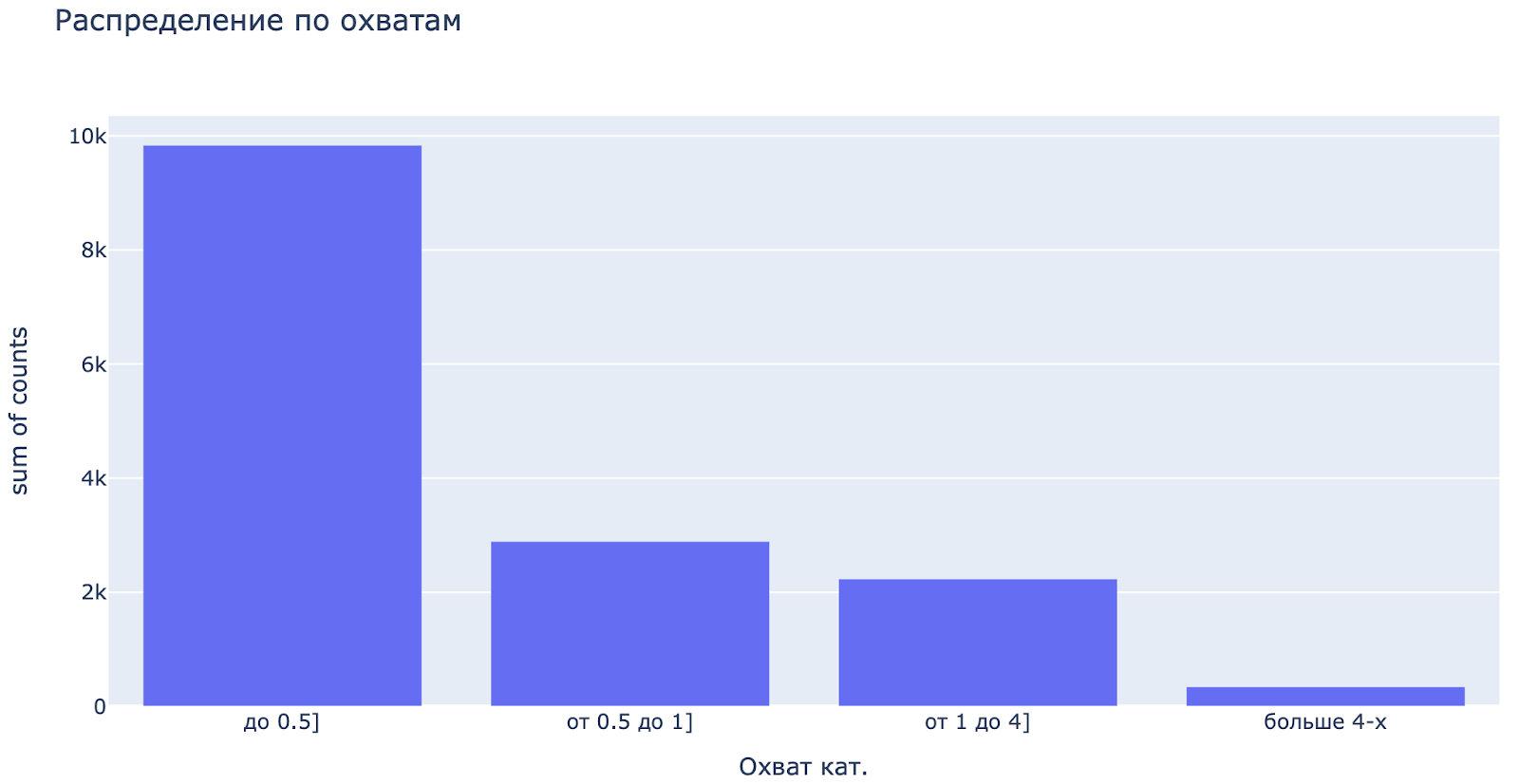
Картинка 5. Коэффициенты вовлеченности и охвата как категориальные переменные.
Мы снова обучили модель KNN с учетом новой категориальной логики. Получилась хорошая средняя точность – 94%, но при этом важность параметров по метрике перестановок оказалась очень низкая. Это значит, что модель почти не использует информацию из этих параметров для предсказания. Скорее всего, она чаще предсказывает самую большую группу (коэффициент до 0.5), и это дает высокую точность просто потому, что эта группа чаще всего встречается в данных. В этой модели в топ самых важных параметров тоже вышла длина текста, как и в предыдущих экспериментах с данными.
Затем мы снова применили XGBoost с учетом разделения на категории. Получилась общая точность 94%, но при анализе по категориям (длина текста, число эмодзи и т.д.) точность вышла всего 20%. Это значит, что модель предсказывает самую массовую группу намного лучше, чем остальные.
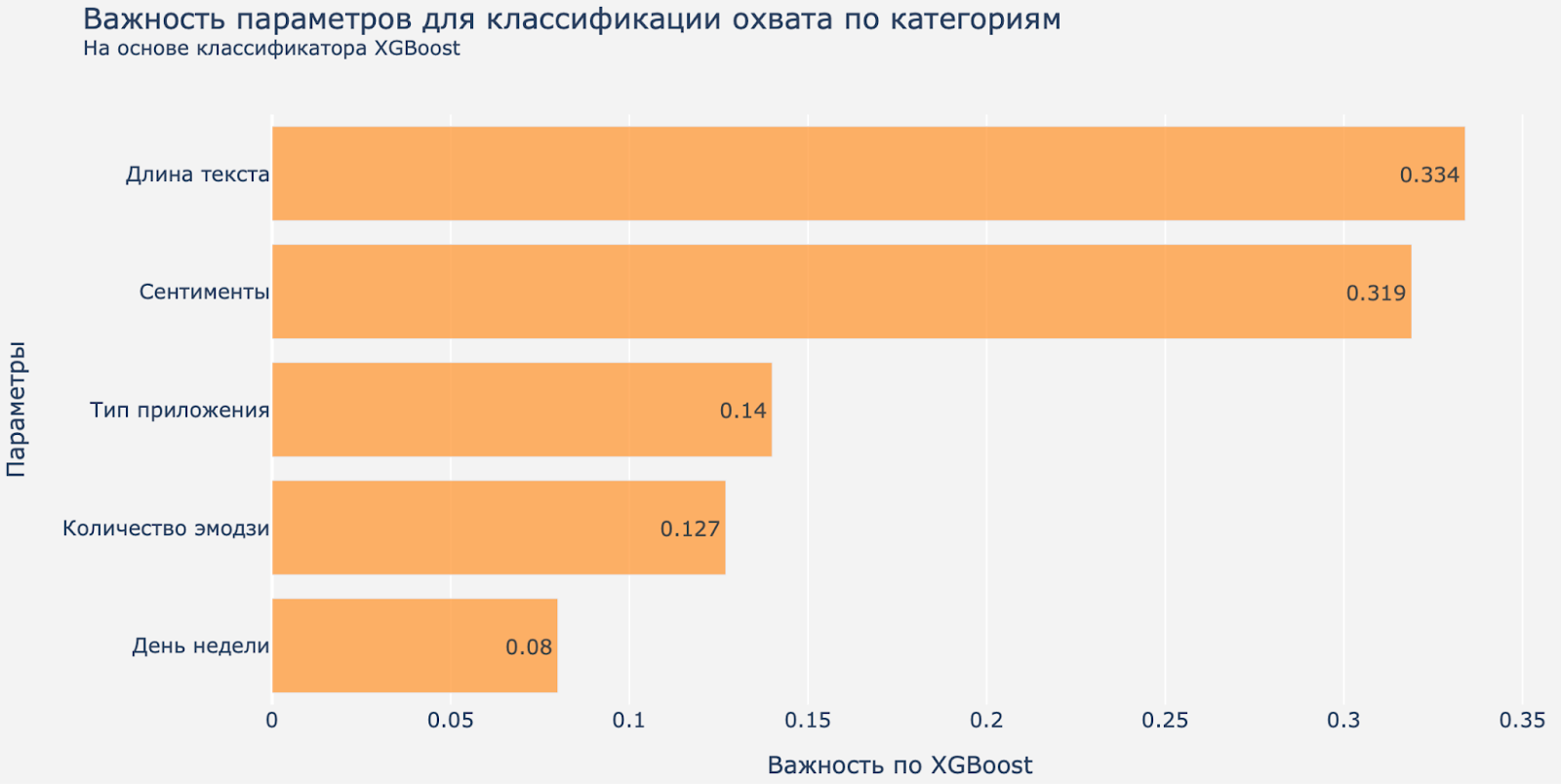
Картинка 7. Важность параметров для коэффициента охвата на основе классификатора XGBoost.
По важности параметров на первое место снова вышла длина текста, а на втором месте в этой модели сентименты (эмоциональная окраска текстов).
Выводы
Мы узнали, что параметр, который сильнее всего влияет на коэффициенты охвата и вовлеченности ВКонтакте, — длина текста. На втором месте эмоциональная окраска — позитивные тексты имеют более высокие коэффициенты охвата и вовлеченности, чем негативные. Но самый главный вывод из этого анализа в том, что количественные параметры не так важны для коэффициента охвата, и нужно уделять больше внимания параметрам, связанным с контентом.
Если сравнивать вовлеченность пользователей в группах НКО ВКонтакте с Instagram и Telegram, то результаты отличаются. Мы думаем, что, в основном, это связано с тем, что в соцсети ВКонтакте мы изучали только политически нейтральных акторов (мы не брали прокремлевские и провоенные группы, а антивоенные и оппозиционные не могут существовать в этой социальной сети из-за цензуры). В то время как в других исследованиях у нас были антивоенные акторы, а в исследовании по Telegram были еще и милитаристские. В Instagram самыми важными параметрами для нейтральных акторов были темы постов, на втором месте формат (фото/альбом/видео) и на третьем эмодзи (которые скоррелированы с длиной текста). То есть формат поста был важнее длины текста и количества эмодзи, посты с каруселью фотографий (с альбомом) были самыми популярными. В Telegram самыми важными параметрами оказались параметры, связанные с частотой постинга. На втором месте было отношение к войне, а на третьем наличие приложений к посту.
