
На дворе — информационые войны и массовая дезинформация; автоматические инструменты фактчекинга становятся по-настоящему важными. Теплица социальных технологий разрабатывает телеграм-бот «Докопался!» (t.me/dokopalsya_bot) — инструмент, который помогает пользователям быстро проверять сомнительные утверждения из новостей, соцсетей и мессенджеров.
Это вторая статья из серии о технологических решениях, которые делают проверку фактов быстрее и доступнее для обычных людей. В первой части мы тестировали, какая языковая модель лучше справляется с проверкой фактов. Сегодня разбираем предыдущий этап — как научить ИИ выбирать из текста именно те утверждения, которые можно и нужно проверять.
Проблема: когда фактчекер проверяет «не то»
Факт-чекинг по сути состоит из двух этапов:
- выделить из текста проверяемые утверждения;
- проверить их по надёжным источникам.
Представьте конвейер: сначала бот разбирает ваше сообщение на отдельные утверждения (это первый этап), затем каждое утверждение проверяется по базам данных и надёжным источникам (это второй этап). Если на первом этапе бот выделит «неправильные» утверждения — вся дальнейшая проверка пойдёт насмарку.
Ранее мы улучшали второй шаг — собственно проверку утверждений. Но по пути всплыла боль: часть «утверждений» нельзя адекватно проверить. Им не хватает контекста или они вовсе не факты, а мнения.
Вот типичные примеры из утверждений, выделенных из пользовательских запросов:
«Цены на поездки могут заметно вырасти из-за массовой замены машин в таксопарках». — Потерян контекст: где, когда, насколько.
«Война является продолжением политики» — философское высказывание, а не проверяемый факт.
Если на вход проверяющему модулю попадает такое сырьё, итоговый вердикт предсказуемо «шумный». Значит, улучшать нужно источник шума — этап извлечения.
«Шумный» вердикт — это когда бот пытается проверить непроверяемое и выдаёт бессмысленный ответ. Например, на философскую фразу «война — продолжение политики» бот может найти цитату из Клаузевица, но это не факт-чек, а литературная справка. Пользователь останется в недоумении.
Три метрики против фейков: какие они?
Чтобы улучшить этап извлечения, мы можем протестировать разные модели и промпты. Но возникла задача: как измерить, что новый подход работает лучше старого? Нельзя же просто «на глазок» сказать, что стало лучше. Мы изучили исследования по извлечению утверждений (см., например, Claim Check-Worthiness Detection: How Well do LLMs Grasp Annotation Guidelines?, Towards Effective Extraction and Evaluation of Factual Claims) и и адаптировали три релевантные нам метрики: decontextualization, verifiability, check-worthiness.
Почему эти три:
Verifiability (проверяемость). Отсекает мнения и расплывчатые формулировки: в поток проверки попадают только факты, которые можно подтвердить источниками.
Пример: «Байден старый» — это мнение, проверить нельзя. «Байдену 82 года» — это факт, можно проверить по официальным данным.
Decontextualization (самодостаточность). Снижает ошибки из-за недостающих деталей (кто/где/когда). Мы оцениваем, меняет ли добавление контекста итоговый вердикт.
Пример: «Цены выросли на 20%» — непонятно, цены на что, где, за какой период. «Цены на бензин в Москве выросли на 20% за последний месяц» — полноценное утверждение, которое можно проверить.
Check-worthiness (значимость). Помогает не тратить ресурсы на банальности: приоритизируем то, что важно для аудитории и потенциально влияет на людей.
Пример: «Вода мокрая» — проверяемый факт, но совершенно бессмысленный для проверки. «Вода в Москве-реке превысила допустимые нормы загрязнения» — важное утверждение, которое нужно проверить.
Проверка полученных утверждений осуществлялась также с помощью LLM. Для этого использовалась модель openai-5 с задачей поставить каждому извлеченному утверждению оценку по нашим трем метрикам:
- Decontextualization / Самодостаточность — 4х бальная шкала;
- Verifiability / Проверяемость — да / нет;
- Check-worthiness / Значимость — 3х бальная шкала.
Да, это выглядит как «ИИ проверяет работу другого ИИ», но это стандартная практика в machine learning. GPT-5 использовался как «судья», потому что он более мощный и может объективно оценить качество работы «младших» моделей. Это как опытный редактор проверяет работу стажёра — принцип тот же.
Также для нас был важен критерий скорости работы модели, так как он сильно влияет на пользовательский опыт: первое, что бот отправляет пользователю — какие утверждения он будет проверять. Если бот думает 30 секунд, пользователь успеет закрыть чат и забыть, зачем вообще что-то проверял. Нужно стремиться к скорости в 2-3 секунды — это комфортно, как ожидание ответа в обычной переписке.
Эксперимент на людях: никакой синтетики
Многие исследователи тестируют AI-модели на искусственно созданных наборах данных — это быстрее и дешевле. Мы же взяли настоящие вопросы от реальных пользователей бота, включая опечатки, сленг, эмоциональные высказывания. Это честный тест в «боевых» условиях, а не лабораторный эксперимент.
Мы протестировали:
- 3 варианта промптов: текущий, улучшенный на основе научных рекомендаций, и улучшенный с ограничением до 3 утверждений на текст
- 5 моделей: openai-5, openai-4o, openai-4o-mini, openai-5-mini, openai-5-nano
Тестировали на реальных запросах пользователей — никаких синтетических данных.
Первый сюрприз: «легкие» модели из новой 5-той линейки OpenAi (GPT-5-nano и GPT-5-mini) оказались слишком слабыми для нашей задачи и сразу выбыли из гонки. Nano и mini — это облегчённые версии GPT-5, созданные для простых задач вроде классификации или коротких ответов. Оказалось, что извлечение утверждений — слишком сложная задача для них. Они путались, выделяли мусор или пропускали важное.
Остальные 3 модели (openai-5, openai-4o, openai-4o-mini) показали довольно близкие результаты. При этом скорость обработки была приемлемой для всех моделей — 2-3 секунды на запрос.
Поэтому мы остановились на той же модели, что используется сейчас — openai-4o-mini. GPT-4o-mini стоит в несколько раз дешевле полной версии GPT-4o, но показывает почти такое же качество. Для некоммерческого проекта вроде Теплицы это критично — позволяет обрабатывать тысячи запросов в месяц без огромных затрат на API.
А вот промпт повлиял на результаты существенно.
Результаты: меньше воды, больше пользы
Лучшие результаты показала связка GPT-4o-mini с ограниченным промптом (до 3 утверждений):
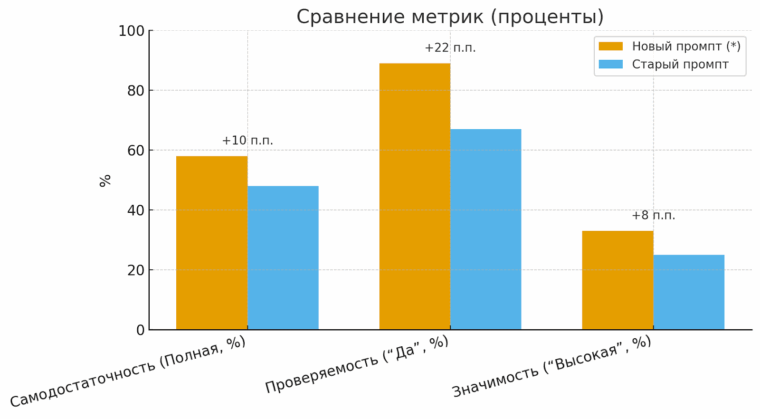
| Метрика | Новый промпт (*) | Старый промпт | Прирост |
| Самодостаточность (Полная, %) | 58% | 48% | +10 п.п. |
| Проверяемость (“Да”, %) | 89% | 67% | +22 п.п. |
| Значимость (“Высокая”, %) | 33% | 25% | +8 п.п. |
| Сводное качество (0–6) | 4.06 | 3.45 | +0.61 |
График показывает, что новый промпт улучшил все три ключевые метрики. Особенно заметен скачок в проверяемости — на 22 процентных пункта. Это значит, что теперь почти 9 из 10 утверждений, которые выделяет бот, действительно можно проверить по источникам.
Интересно, что ограничение количества извлекаемых утверждений до трех существенно увеличило качество. Скорее всего, это ограничение заставило модель выбирать только самые важные и качественные утверждения вместо того, чтобы «цепляться» за каждую мелочь.
Когда мы разрешили боту выделять неограниченное количество утверждений, он начинал дробить текст на десятки мелких фрагментов, многие из которых были бессмысленными. Ограничение «максимум 3 утверждения» заставило ИИ работать избирательно — как опытный редактор, который выбирает только самое главное.
| Вариант промпта | Проверяемость (“Да”, %) |
| Старый промпт | 67% |
| Новый промпт | 83% |
| Новый с ограничением | 89% |
Эта таблица показывает эволюцию подхода: каждая итерация давала прирост качества. Финальная версия с ограничением оказалась лучшей.
Вот как меняется выдача на одинаковых запросах.
(1) Про сети «Красное и белое» и «Бристоль»: старый промпт разрывает мысль на два факта — «„Красное и белое» принадлежат одному владельцу» и «„Бристоль» принадлежит одному владельцу»; новый промпт собирает их в одно проверяемое утверждение: «„Красное и белое» и „Бристоль» принадлежат одному владельцу».
Почему это лучше? Два разорванных утверждения требуют двух отдельных проверок, которые по отдельности бессмысленны. Объединённое утверждение проверяется один раз и даёт пользователю полный ответ.
Что изменилось в самом боте? Вместо заключения
По результатам исследования мы:
- Внедрили новый промпт с ограничением на количество утверждений
- Остановились на GPT-4o-mini как оптимальное соотношение цена-качество
- Заменили модель для факт-чекинга на GPT-4o-search (по результатам предыдущего теста).
Почему «Докопался!» уникален
Разработка «Докопался!» — это часть глобального тренда на автоматизацию факт-чекинга. Похожие проекты есть по всему миру. Однако в отличие от коммерческих решений на тему автоматизированного фактчекинга вроде Originality.ai (для издателей) или Meedan Check ($400-2900/месяц) , «Докопался!» — это некоммерческий инструмент, бесплатный для пользователей и созданный специально для русскоязычной аудитории.
Вы можете помочь улучшить @dokopalsya_bot:
— Отправляйте боту любые сомнительные утверждения из новостей или соцсетей;
— Оценивайте полезность проверок (для этого в интерфейсе есть специальные кнопки);
Каждый ваш запрос делает бота умнее — мы анализируем все взаимодействия и используем их для дальнейшего улучшения алгоритмов.