
Web Robots – это платформа, которая позволяет извлекать статические и динамические данные с сайтов и добавлять их в свои базы данных для последующего использования.
Такой процесс сбора данных называется скрапингом, парсингом или краулингом. Эти данные можно найти на страницах сайтов, а также с помощью поисковых систем. Ранее мы уже писали о magic.import.io – подобном сервисе для извлечения данных.
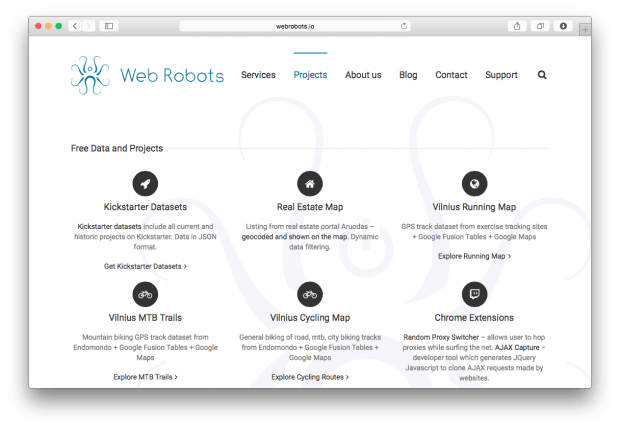
В разделе Projects можно найти примеры баз данных и визуализаций на основе извлеченных данных с сайтов.
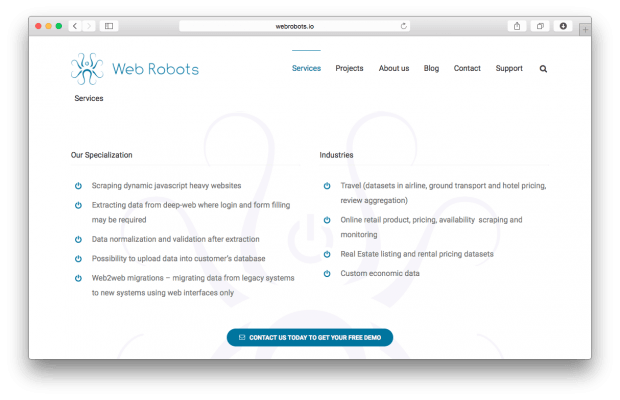
В разделе Сервисы показаны возможности платформы по извлечению данных. Так, можно извлекать динамические JavaScript-сайты, загружать данные в сторонние базы данных и т.д.
О том, как начать работу с платформой, можно узнать в разделе Scraping Tutorial, в котором представлена пошаговая инструкция. Для разработчиков по Web Robots есть полная документация.